Anomaly Detection Service – 模块
Anomaly Detection Service 由模型训练或聚类模块以及模型应用或评分模块组成。

模型训练(聚类)
模型训练模块对 API 调用中指定的历史训练数据集进行聚类操作,为流程/asset 提供了一个正常行为模型。使用 DBSCAN 算法进行聚类(根据 Ester、Martin 等人的研究,DBSCAN 是“一种基于密度的算法,适用于在带有噪声的大型空间数据库中发现聚类。”Kdd.1996 年第 96 卷第 34 号)。聚类为每个数据实例分配其所属的群集 ID,如果其不属于任何群集,则分配噪声标签。对于群集中数据点保存此信息即可,并且此群集内的邻居数量至少为最小群集大小。
该算法使用以下参数:
epsilon:用于确定某点是否属于群集的距离阈值minPointsPerCluster:最小群集大小distanceMeasureAlgorithm(可选):要应用的距离测量算法:- 欧氏距离(默认)
- 曼哈顿距离
- 切比雪夫距离
name(可选):便于记忆的模型名称(默认:“模型”)。
Model Management Service 适用于模型存储,并自动将模型的过期日期设置为 14 天。可更改此参数。
优势
- 无监督学习方法 → 无需标记的训练数据
- 适用于单变量和多变量时间序列以及时间序列子序列
- 在训练数据中存在噪声时非常稳健
- 可扩展为分布式聚类
- 快速测试阶段 → 可扩展用于实时分析
- 允许人类交互和 domain 知识的集成(例如通过标记新的群集和/或异常)
备注
- 该方法中,高度依赖于分析数据的输入参数必填(聚类参数、距离测量)。
- 对于形成具有显著不同密度值的群集或根本没有群集的数据,此方法不可行。
- 模型训练(聚类)的复杂性为 O(n2)。
- 异常可能会形成群集并导致漏报。
- 在模型训练和应用之前,需要对数据进行预处理(标准化、季节性、分段等)。
模型应用(评分)
模型应用模块可用于确定给定的一组数据点是否异常。通过计算每个数据点 p 到其最近邻居 n(即核心点)的距离来确定是否异常。如果该距离小于或等于 epsilon,则该数据点没有发生异常。这些数据点的得分为 0。在其它情况下,数据点的得分等于距离和 epsilon 之间的差值。分数越高,数据点异常的可能性就越大。
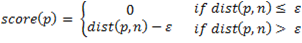
为了确保可扩展性和对不同用例的适用性,Anomaly Detection Service 提供了各种可用于聚类和评分的距离函数。目前,Anomaly Detection Service 支持欧氏距离、曼哈顿距离和切比雪夫距离。
还有问题?
除非另行声明,该网站内容遵循MindSphere开发许可协议.
Last update: June 26, 2019