SDI nodes¶
Usage of SDI nodes¶
The following listing shows the Semantic Data Interconnect (SDI) nodes and their respective functions:
SDI create query¶
Simple Anomaly node library¶
Introduction to simple anomaly nodes¶
The anomaly nodes help to detect anomalies in a data set.
The simple anomaly nodes in Visual Flow Creator are of two types:
- Training model
- Reasoning model
Terms and definitions¶
Cluster: A cluster is a high density region in a defined space. Each cluster is a set of data points which defines a dense region.
Anomaly points: The number of anomaly points available outside a data cluster.
Neighborhood: The neighborhood of a point is a set of all points that are within a distance set by the neighborhood parameter.
Epsilon (ε or eps): The epsilon (ε) defines the distance defined of neighborhood around a certain point in the selected algorithm (Euclidean, Manhattan, Chebychev).
Anomaly extent: Distance between an anomaly point and its centre point (ε) of the cluster. Anomalies are minimal for lesser anomaly extents. For greater distances, anomalies are larger.
Algorithms: Euclidean: The Euclidean distance is defined by a straight line between two points. Manhattan: The Manhattan distance measure algorithm finds its application on high dimensional vectors. The sum of the absolute differences among their coordinates is defined as the distance between two points. Chebychev: The maximum distance from the centre of a cell to its adjacent cells centre is defined as the Chebychev distance between two points.
Training model node¶

The training model node defines a new model of some data sets in Visual Flow Creator.
The data set information gets configured as read time series node with one condition - you can select only one aspect. The data set is defined by asset/ aspect/ variable. The data set can be selected using "Select asset aspect" selection dialog box.
Training model created will be stored in Industrial IoT exchange storage.
Training model node properties¶
You can configure the node by editing its node properties.
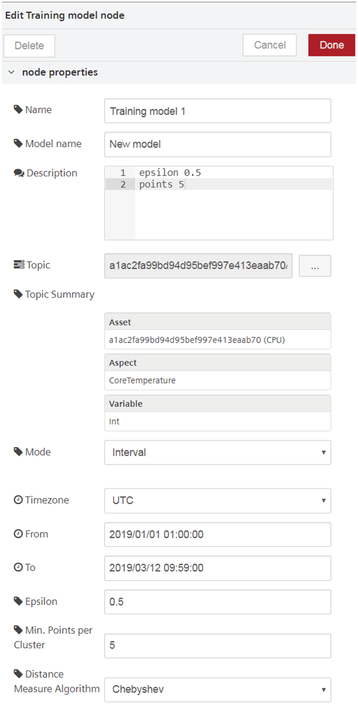
| Field Name | Description | Mandatory |
|---|---|---|
| Name | Select a display name for the node. | No |
| Model Name | Name the new training model. | Yes |
| Description | Enter the description. | No |
| Topic | Import the required time series data from the "Topic" field. The menu will | Yes |
| redirect to select read time series data with | ||
| asset /aspect variable. | ||
| Topic Summary | Each asset will have aspects which are defined by variables. Select the required | Yes |
| variable of the selected aspect of its asset to import the data in the | ||
| "Training model" node properties. This will autofill the "Topic Summary" | ||
| Mode | Select the mode from the drop-down menu. "Mode" is either defined by period of | Yes |
| time or an interval. | ||
| Period | ||
| Period | Select the time period from the drop-down menu. The time period drop-down has | Yes |
| values defined in minutes, hours, days and weeks. | ||
| Offset | Select the offset value for balancing the effects. The offset values are | Yes |
| defined in seconds. | ||
| Interval | ||
| Timezone | Select the required time zone from the drop-down menu. | Yes |
| From | Select the start date and time from the calendar and time menu. | Yes |
| To | Select the end date and time from the calendar and time menu. | Yes |
| Epsilon | Set the ε for the new model. | Yes |
| Min. points per cluster | Define the minimum number of points which are in each cluster. | Yes |
| Distance Measure Algorithm | Select the required distance measure algorithm from the drop-down. | Yes |
| Three algorithms are available: | ||
| - Euclidean | ||
| - Manhattan | ||
| - Chebychev |
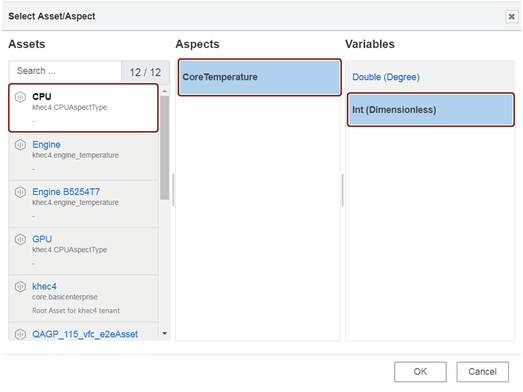
When you set the topic in "Select Asset/ Aspect" dialog box, select the necessary asset, aspect and its variable as shown below:
Jobs run involved¶
While injecting a timestamp to the "training model" node, a set of batch jobs run in the following series:
- Fetching IoT data
- Create model job
- Export job and generating output
Reasoning model node¶
The reasoning model node is used for analyzing data for a stored training model.

Reasoning model node properties¶
You can configure the node by editing its node properties.
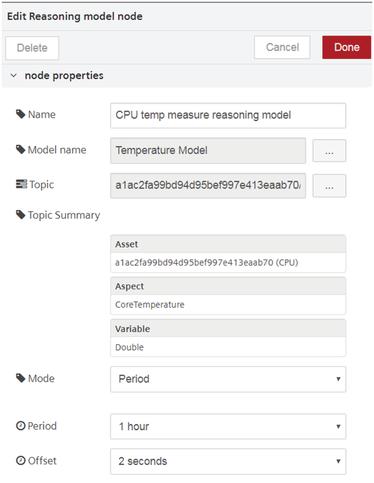
| Field Name | Description | Mandatory |
|---|---|---|
| Name | Select a display name for the node. | No |
| Model Name | Select a training model from the menu. | Yes |
| Description | Enter the description. | No |
| Topic | Import the required time series data from the "Topic" field. The menu will | Yes |
| redirect to select read time series data with asset /aspect /variable. | ||
| The import will capture the actual details of the model selected. However, | ||
| the aspects and variables imported should be same as that selected for | ||
| the "Model Name". | ||
| Topic Summary | Each asset will have aspects which are defined by variables. Select the required | Yes |
| variable of the selected aspect of its asset to import the data in the | ||
| "Training model" node properties. This will autofill the "Topic Summary" field. | ||
| Mode | Select the mode from the drop-down menu. "Mode" is either defined by period of | Yes |
| time or an interval. | ||
| Period | ||
| Period | Select the time period from the drop-down menu. The time period drop-down has | Yes |
| values defined in minutes, hours, days and weeks. | ||
| Offset | Select the offset value for balancing the effects. The offset values are defined | Yes |
| in seconds. | ||
| Interval | ||
| Timezone | Select the required time zone from the drop-down menu. | Yes |
| From | Select the start date and time from the calendar and time menu. | Yes |
| To | Select the end date and time from the calendar and time menu. | Yes |
When you select a model name, the data of the selected model will be imported to the reasoning model node for analysis.
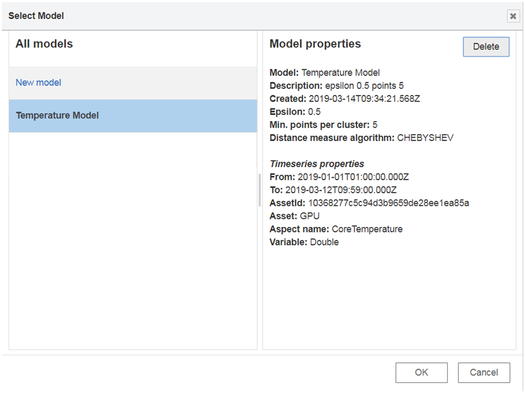
The property details of the selected model will also be displayed to the user.
Jobs run involved¶
While injecting a timestamp to the "reasoning model" node, a set of batch jobs run in the following series:
- IoT import job creation
- Import the job model
- Apply the job model
- Export the job and save in the database
Using simple anomaly nodes¶
Example scenario¶
Configure a training model node. Analyze the anomalies in the model.
Objective¶
To analyze the anomalies in the newly created training model with the help of a reasoning model node.
Requirements¶
Import the data from Insights Hub Monitor to create a training model.
Configuration of the training model is given below:
| Field Name | Data |
|---|---|
| Name | CPU temp measure |
| Model Name | Temperature Model |
| Description | epsilon 0.5 |
| points 5 | |
| Topic | 10368277c5c94d3b9659de28ee1ea85a |
| Topic Summary | Asset: 10368277c5c94d3b9659de28ee1ea85a (GPU) |
| Aspect: CoreTemperature | |
| Variable: Double | |
| Mode | Interval |
| Period | |
| Timezone | UTC |
| From | 2019/01/01 01:00:00 |
| To | 2019/03/12 09:59:00 |
| Epsilon | 0.5 |
| Min. points per cluster | 5 |
| Distance Measure Algorithm | Chebychev |
Procedure¶
- Select a reasoning model node from the "simple anomaly" nodes section.
-
Configure the reasoning model node. The configuration of the node is given below:
Field Name Data Name CPU temp measure reasoning model Model Name Temperature Model Topic a1ac2fa99bd94d95bef997e413eaab70 Topic Summary Asset: a1ac2fa99bd94d95bef997e413eaab70 (CPU) Aspect: CoreTemperature Variable: Double Mode Period Period Period 1 hour Offset 2 seconds -
Insert an input timestamp and a message payload to the reasoning model node to generate the output in the message payload.

Note
The "Topic Summary" properties in training model node should match the "Topic Summary" properties of the reasoning model node. This means that aspects and the variables for both should be same else the output will conflict and result in a failure.
Result¶
Inject the timestamp to process the flow.
You get the following result in the message payload:
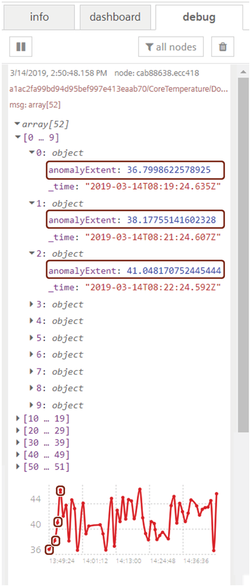
Some of the initial anomaly points are highlighted in the graph as well in the array description.
Simple Anomaly node library¶
Introduction to simple anomaly nodes¶
The anomaly nodes help to detect anomalies in a data set.
The simple anomaly nodes in Visual Flow Creator are of two types:
- Training model
- Reasoning model
Terms and definitions¶
Cluster: A cluster is a high density region in a defined space. Each cluster is a set of data points which defines a dense region.
Anomaly points: The number of anomaly points available outside a data cluster.
Neighborhood: The neighborhood of a point is a set of all points that are within a distance set by the neighborhood parameter.
Epsilon (ε or eps): The epsilon (ε) defines the distance defined of neighborhood around a certain point in the selected algorithm (Euclidean, Manhattan, Chebychev).
Anomaly extent: Distance between an anomaly point and its centre point (ε) of the cluster. Anomalies are minimal for lesser anomaly extents. For greater distances, anomalies are larger.
Algorithms: Euclidean: The Euclidean distance is defined by a straight line between two points. Manhattan: The Manhattan distance measure algorithm finds its application on high dimensional vectors. The sum of the absolute differences among their coordinates is defined as the distance between two points. Chebychev: The maximum distance from the centre of a cell to its adjacent cells centre is defined as the Chebychev distance between two points.
Training model node¶
The training model node defines a new model of some data sets in Visual Flow Creator.
The data set information gets configured as read time series node with one condition - you can select only one aspect. The data set is defined by asset/ aspect/ variable. The data set can be selected using "Select asset aspect" selection dialog box.
Training model created will be stored in Industrial IoT exchange storage.
Training model node properties¶
You can configure the node by editing its node properties.
| Field Name | Description | Mandatory |
|---|---|---|
| Name | Select a display name for the node. | No |
| Model Name | Name the new training model. | Yes |
| Description | Enter the description. | No |
| Topic | Import the required time series data from the "Topic" field. The menu will | Yes |
| redirect to select read time series data with | ||
| asset /aspect variable. | ||
| Topic Summary | Each asset will have aspects which are defined by variables. Select the required | Yes |
| variable of the selected aspect of its asset to import the data in the | ||
| "Training model" node properties. This will autofill the "Topic Summary" | ||
| Mode | Select the mode from the drop-down menu. "Mode" is either defined by period of | Yes |
| time or an interval. | ||
| Period | ||
| Period | Select the time period from the drop-down menu. The time period drop-down has | Yes |
| values defined in minutes, hours, days and weeks. | ||
| Offset | Select the offset value for balancing the effects. The offset values are | Yes |
| defined in seconds. | ||
| Interval | ||
| Timezone | Select the required time zone from the drop-down menu. | Yes |
| From | Select the start date and time from the calendar and time menu. | Yes |
| To | Select the end date and time from the calendar and time menu. | Yes |
| Epsilon | Set the ε for the new model. | Yes |
| Min. points per cluster | Define the minimum number of points which are in each cluster. | Yes |
| Distance Measure Algorithm | Select the required distance measure algorithm from the drop-down. | Yes |
| Three algorithms are available: | ||
| - Euclidean | ||
| - Manhattan | ||
| - Chebychev |
When you set the topic in "Select Asset/ Aspect" dialog box, select the necessary asset, aspect and its variable as shown below:
Jobs run involved¶
While injecting a timestamp to the "training model" node, a set of batch jobs run in the following series:
- Fetching IoT data
- Create model job
- Export job and generating output
Reasoning model node¶
The reasoning model node is used for analyzing data for a stored training model.
Reasoning model node properties¶
You can configure the node by editing its node properties.
| Field Name | Description | Mandatory |
|---|---|---|
| Name | Select a display name for the node. | No |
| Model Name | Select a training model from the menu. | Yes |
| Description | Enter the description. | No |
| Topic | Import the required time series data from the "Topic" field. The menu will | Yes |
| redirect to select read time series data with asset /aspect /variable. | ||
| The import will capture the actual details of the model selected. However, | ||
| the aspects and variables imported should be same as that selected for | ||
| the "Model Name". | ||
| Topic Summary | Each asset will have aspects which are defined by variables. Select the required | Yes |
| variable of the selected aspect of its asset to import the data in the | ||
| "Training model" node properties. This will autofill the "Topic Summary" field. | ||
| Mode | Select the mode from the drop-down menu. "Mode" is either defined by period of | Yes |
| time or an interval. | ||
| Period | ||
| Period | Select the time period from the drop-down menu. The time period drop-down has | Yes |
| values defined in minutes, hours, days and weeks. | ||
| Offset | Select the offset value for balancing the effects. The offset values are defined | Yes |
| in seconds. | ||
| Interval | ||
| Timezone | Select the required time zone from the drop-down menu. | Yes |
| From | Select the start date and time from the calendar and time menu. | Yes |
| To | Select the end date and time from the calendar and time menu. | Yes |
When you select a model name, the data of the selected model will be imported to the reasoning model node for analysis.
The property details of the selected model will also be displayed to the user.
Jobs run involved¶
While injecting a timestamp to the "reasoning model" node, a set of batch jobs run in the following series:
- IoT import job creation
- Import the job model
- Apply the job model
- Export the job and save in the database
Using simple anomaly nodes¶
Example scenario¶
Configure a training model node. Analyze the anomalies in the model.
Objective¶
To analyze the anomalies in the newly created training model with the help of a reasoning model node.
Requirements¶
Import the data from Insights Hub Monitor to create a training model.
Configuration of the training model is given below:
| Field Name | Data |
|---|---|
| Name | CPU temp measure |
| Model Name | Temperature Model |
| Description | epsilon 0.5 |
| points 5 | |
| Topic | 10368277c5c94d3b9659de28ee1ea85a |
| Topic Summary | Asset: 10368277c5c94d3b9659de28ee1ea85a (GPU) |
| Aspect: CoreTemperature | |
| Variable: Double | |
| Mode | Interval |
| Period | |
| Timezone | UTC |
| From | 2019/01/01 01:00:00 |
| To | 2019/03/12 09:59:00 |
| Epsilon | 0.5 |
| Min. points per cluster | 5 |
| Distance Measure Algorithm | Chebychev |
Procedure¶
- Select a reasoning model node from the "simple anomaly" nodes section.
-
Configure the reasoning model node. The configuration of the node is given below:
Field Name Data Name CPU temp measure reasoning model Model Name Temperature Model Topic a1ac2fa99bd94d95bef997e413eaab70 Topic Summary Asset: a1ac2fa99bd94d95bef997e413eaab70 (CPU) Aspect: CoreTemperature Variable: Double Mode Period Period Period 1 hour Offset 2 seconds -
Insert an input timestamp and a message payload to the reasoning model node to generate the output in the message payload.
Note
The "Topic Summary" properties in training model node should match the "Topic Summary" properties of the reasoning model node. This means that aspects and the variables for both should be same else the output will conflict and result in a failure.
Result¶
Inject the timestamp to process the flow.
You get the following result in the message payload:
Some of the initial anomaly points are highlighted in the graph as well in the array description.

This node allows to create a query and retrieve the data. Query can be static or dynamic. The flow generates the output with a query ID and the data will be stored for further analysis.
SDI execution job¶

This node allows to execute a job for the dynamic queries. The query ID generated from the sdi create query node should be mentioned in the node properties of the sdi execution job node. The flow generates the output with execution job ID and the data will be stored for further analysis.
SDI query results¶

This node shows the result for a query and it retrieves both static and dynamic data. The query ID and execution job ID should be mentioned in the node properties. The flow generates the output and the data will be stored for further analysis.
Note
If the flow is static, execution job ID is not required.
SDI ingest status¶

This node allows to get the status of the SDI ingest jobs. You can query the list of all ingest jobs or a single one.
Using SDI nodes¶
In order to use the SDI nodes with the integrated data lake (IDL), you have to do some preparation work. You cannot do that in VFC, but have to use the Insights Hub APIs. The steps are:
- Connect IDL to SDI (create a data lake record)
- Create a data registry
- Upload your data to IDL
Make sure that you upload the data in the "sdi" directory and add the meta-tag:
"registryid_{yourregistryid}"
If these requirements are fulfilled, SDI will be able to use the data.
See the SDI documentation for further details.
You can use these SDI nodes to create queries, execution jobs and execute queries.
Example scenario¶
Retrieve the dynamic data from the create queries, execution jobs and execute queries.
Objective¶
To retrieve the dynamic data from the create queries, execution jobs and execute queries and store it for further analysis.
SDI create query node procedure¶
To use SDI create query node, follow these steps:
- Select the "sdi create query" node from the "data Lake and sdi" palette.
- Connect the inject node with sdi create query node and debug node as shown below:

- Double click the sdi create query node to edit the properties:
- Name: My new query
- Description: Creating a query
- Dynamic: Yes
- SQL Statement: SELECT airnow_aqi.parametername,airnow_aqi.reportingunits,airnow_aqi.value from airnow_aqi where airnow_aqi.sitename=:"airnow_aqi.sitename"
- Save and deploy.
SDI create query output¶
The output is displayed in the debug window:
SDI Create Query node output¶
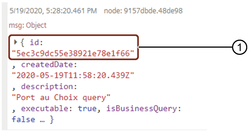
① Query ID
SDI execution job node procedure¶
The SDI execution job is used to create dynamic queries only. For more information, see SDI execution job.
To use SDI execution job node, follow these steps:
- Select the "sdi execution job" node from the "data Lake and sdi" palette.
- Connect the inject node with sdi execution job node and debug node as shown below:

- Double click the sdi execution job node to edit the properties:
- Name: execution job for WELLINGTON
- Description: creating execution job
- Query ID: 5ec3c9dc55e38921e78e1f66
- Parameters: Name="airnow_aqi.sitename" and Value="WELLINGTON"
- Save and deploy.
SDI execution job output¶
The output is displayed in the message payload:
SDI execution job node output¶
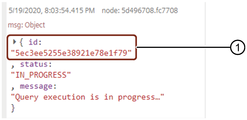
① Execution job ID
Note
Execution job node is only for dynamic queries.
SDI query results node procedure¶
To use SDI query results node, follow these steps:
- Select the "sdi query results" node from the "data Lake and sdi" palette.
- Connect the inject node with sdi query results node and debug node as shown below:

- Double click the sdi create query node to edit the properties:
- Name: sdi query results
- Query ID: 5ec3c9dc55e38921e78e1f66
- Execution job ID: 5ec3ee5255e38921e78e1f79
- Save and deploy.
SDI query results¶
The output is displayed in the message payload:
SDI query result node output¶
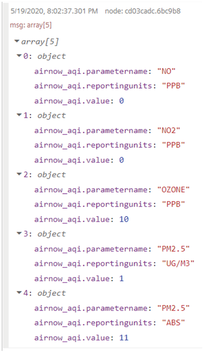
SDI ingest status node procedure¶
The SDI ingest status node is used to get the status of the SDI ingest jobs. For more information, see SDI ingest status.
To use SDI query results node, follow these steps:
- Select the "sdi ingest status" node from the "data Lake and sdi" palette.
- Connect the inject node with sdi ingest status node and debug node as shown below:

- Save and deploy.
SDI ingest status output¶
The output is displayed in the message payload:
SDI ingest status node output¶
